| Search and analysis of amino acid sequences of the three isoforms of glutamate dehydrogenase (EC 1.4.1.[2/3/4]) |
| Tweet |
|
|
A. Search for all amino acid sequences of GDH
The number of hits is indicated on the right of the screen. To see the results ("Summary"), click on this number in your browser. |
|
1. Page "Protein Advanced Search Builder" : fields of the "Builder". In the "History", select your desired search by clicking on either #1 or #2, ... 2. In a new field of the menu, paste the following terms : (this list has not been updated) decarboxylase NOT topoisomerase NOT monooxygenase NOT transaminase NOT kinase NOT oxidase NOT thioredoxin NOT glycerate NOT glyoxylate NOT glucose NOT glutamine NOT glutamyl NOT glucarate NOT glycerol NOT proline NOT valine NOT semialdehyde NOT aldehyde NOT glyceraldehyde NOT dihydropyrimidine NOT formyltetrahydrofolate NOT fatty NOT isocitrate NOT saccharopine NOT methylmalonate NOT coenzyme NOT glutathione NOT quinone NOT ammonium NOT histidinol NOT carboxylate NOT alcohol NOT purine NOT sulfide NOT putative NOT similar NOT hypothetical NOT probable NOT related NOT similarity NOT homolog NOT homologue NOT synthetic NOT unknown NOT mutant NOT unnamed NOT imported NOT validated NOT partial NOT peptide NOT chain NOT line NOT tentative NOT supported NOT patent NOT expressed NOT transcript NOT precursor NOT collection NOT regulator NOT anion NOT yweB NOT ypcA NOT NAGSA NOT P5C NOT GSA NOT RIKEN 3. Click on boolean "NOT". All keywords and booleans are written in the main field (top of the page). Click on "Search". Questions :
4. Field "Builder", choose "Sequence length"; Tape : "400:1700"; Select the boolean "AND"; Click on "Search" Question : what is the goal of this selection ? |
|
B. Removing redondant sequences This part is the most tedious and time - consuming one, since for each organism, the redondant sequences must be removed. This can be made using Multalin. Questions :
|
|
|
Go back to the the NCBI search window. 1. Copy the following accession numbers of redondant files to be removed. Paste them in the main field (top of the page of the the NCBI search window) : NOT CAA58312 NOT NP_692731 NOT CAD58715 NOT T49883 NOT CAB87933 NOT AAB01222 NOT S71217 NOT AAA82615 NOT A25275 NOT AAA34642 NOT CAA67475 NOT NP_111279 NOT NP_111278 NOT NP_460265 NOT AAO68835 NOT NP_456213 NOT CAD02055 NOT JN0854 NOT AAL81726 NOT AAA83390 NOT D75176 NOT CAB49491 NOT AAL64915 NOT AAL63869 NOT AAK42230 NOT AAK42099 NOT AAK42126 NOT AAK41684 NOT CAA40341 NOT AAO77080 NOT AAO77077 NOT BAB42058 NOT BAB94705 NOT NP_645657 NOT NP_371482 NOT BAB57120 NOT AAO04251 NOT AE3467 NOT AAL52904 NOT NP_539149 NOT CAD21426 NOT 1919235A NOT CAD63684 NOT NP_761460 NOT NP_761459 NOT AAO35861 NOT AAA62756 NOT AAK78713 NOT AAL94684 NOT AAN80621 NOT AAG56747 NOT CAA25495 NOT AAA87979 NOT AAN00206 NOT AAK99984 NOT AAK75409 NOT AAN24452 NOT AAM87403 NOT AAM24566 NOT AAM24435 NOT CAA51376 NOT BAB75954 NOT S77064 NOT CAA54601 NOT AAG19574 NOT AAG18779 NOT CAA45327 NOT BAB07661 NOT BAB06437 NOT BAB05341 NOT BAB05820 NOT AAC63990 NOT AAB40142 NOT BAA08445 NOT CAB94836 NOT CAA69600 NOT CAA69601 NOT CAA34252 NOT AAA29155 NOT AAB20267 NOT AAA25611 NOT AAN36776 NOT CAA73390 NOT AAK77969 NOT CAA46994 NOT AAA52525 NOT AAM73240 NOT AAB20267 NOT S06938 NOT CAA34434 (This list is indicative.) 3. Click on "Search" :
|
C. Selection of the GDH sequences as a function of the EC number, the Viridiplantae belonging and the size of the polypeptide chain. 1. Subset A : EC 1.4.1.2 isoform from Viridiplantae with amino acids length range [411 : 470] |
| type of GDH | field Add Term(s) | hits ("Search") | ||
| option | tape | boolean | ||
| EC 1.4.1.2 isoform | EC/RN Number | 1.4.1.2 | AND | 20 (*) |
| Viridiplantae | Organism | viridiplantae | AND | 9 |
| length range [411 : 470] | Sequence length | 411:470 | AND | 9 |
| See the taxonomy for Viridiplantae. | ||||
Get the files in FASTA format (compressed) : Subset A (Tgz) |
2. Subset B : EC 1.4.1.2 isoform from NOT Viridiplantae with amino acids length range [411 : 470] Go back to the the "Preview" window (*) : 20 hits (EC 1.4.1.2 isoform) |
| type of GDH | field Add Term(s) | hits ("Search") | ||
| option | tape | boolean | ||
| NOT Viridiplantae | Organism | viridiplantae | NOT | 11 (*) |
| length range [411 : 470] | Sequence length | 411:470 | AND | 8 |
|
Proceed as before for saving. Get the files in FASTA format (compressed) : Subset B (Tgz) |
3. Subset C : EC 1.4.1.2 isoform from NOT Viridiplantae with amino acids length range [1607 : 1651] Go back to the the "Preview" window (*) : 11 hits (NOT Viridiplantae) |
| type of GDH | field Add Term(s) | hits ("Search") | ||
| option | tape | boolean | ||
| length range [411 : 470] | Sequence length | 1607:1651 | AND | 3 |
Proceed as before for saving. Get the files in FASTA format (compressed) : Subset C (Tgz) ... and so on for all other GDH EC 1.4.1.3, EC 1.4.1.3 and NOT EC CLASSIFIED. |
D. Summary of the 116 full sequences of GDH from 83 organisms classified in 15 subsets The table below indicates the number of polypeptide sequences of GDH for each subset (letter). See the classification by organism (Word document - compressed files) => Organisms (Tgz) |
| EC number | Viridiplantae | not Viridiplantae | total | ||||||
| L1 | L2 | L3 | L4 | L1 | L2 | L3 | L4 | ||
| 1.4.1.2 | 9 (A) | 7 (B) | 1 (C) | 17 | |||||
| 1.4.1.3 | 1 (D) | 6 (E) | 7 (F) | 14 | |||||
| 1.4.1.4 | 2 (Ref) | 15 (G) | 17 | ||||||
| not classified | 6 (H) | 13 (I1) 18 (I2) 14 (I3) | 5 (J) | 5 (K) | 7 (L) | 68 | |||
| total | 16 | 2 | 73 | 12 | 5 | 8 | 116 | ||
E. Analysis of the full sequences of GDH classified in 15 subsets Get the GDH sequences from each subset in FASTA format (ZIP compressed) from the table below. The length range of the polypeptide chains are : L1 = [411 : 470] - L2 = [503 : 558] - L3 = [1029 : 1106] - L4 = [1607 : 1651] |
| EC number | Viridiplantae | not Viridiplantae | ||||||
| L1 | L2 | L3 | L4 | L1 | L2 | L3 | L4 | |
| 1.4.1.2 | Subset A | ----- | ----- | ----- | Subset B | ----- | ----- | Subset C |
| 1.4.1.3 | Subset D | ----- | ----- | ----- | Subset E | Subset F | ----- | ----- |
| 1.4.1.4 | ----- | REF | ----- | ----- | Subset G | ----- | ----- | ----- |
| not classified | Subset H | ----- | ----- | ----- | Subset I1 |
Subset J | Subset K | Subset L |
1. Open the file with a text editor. Copy only the data begenning with a ">". 2. Go to Clustal Omega. Paste the data into the window. 3. Select the appropriate matrix and parameters (Examples : matrix = Gonnet / Gapopen = 1 / Gapext = 1 / Other parameters = default value). 4. Run the software. The results are returned. There are links to various types of files : ".aln" for the alignment / ".dnd" for the dendogram. Remark : "Jalview" is a Java multiple alignment editor allowing to make a lot of things [Examples : calculate consensus / adding or removing sequences / pairwise alignment of selected sequences / visualisation of a coloured alignment on the basis of different physico-chemical properties / editing sequences (font, size ...)] 5. Click on the file ".aln" to see the alignment. Save the file. The extension ".aln" allows to use it with various other softwares. |
F. Obtention of the full consensus sequence for each subset
... and so on for all other subsets. |
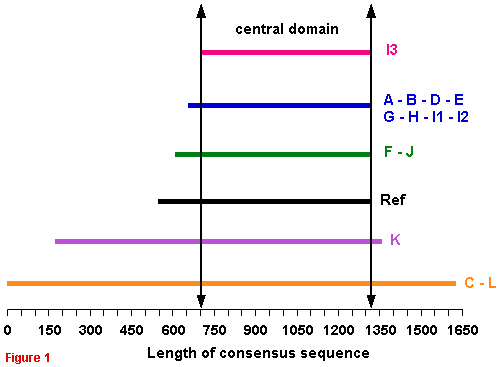
G. Alignment of the 15 full consensus sequences
The alignment of the consensus sequences shows that GDH subunit is constituted of two or three regions :
|
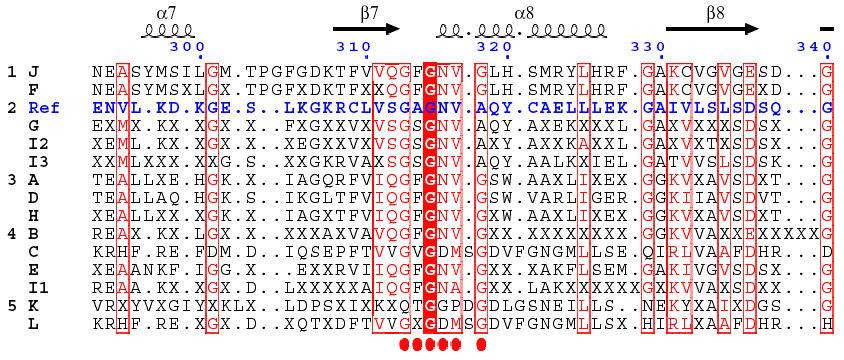
H. Analysis of the central domain of GDH : the dinucleotide-binding motif A β - α - β fold is found in the NAD(P)H-binding subdomain (β7 - α8 - β8). This Rossmann fold begins with the motif G313AGNVA318 in the case of Ref. However, the alignment indicates that the actual motives could be more complex. Such a higher complexity of the signature for the NAD(P)H-binding motif allows to discriminate more precisely the three isoforms.
This figure was generated using the software ESpript.
|
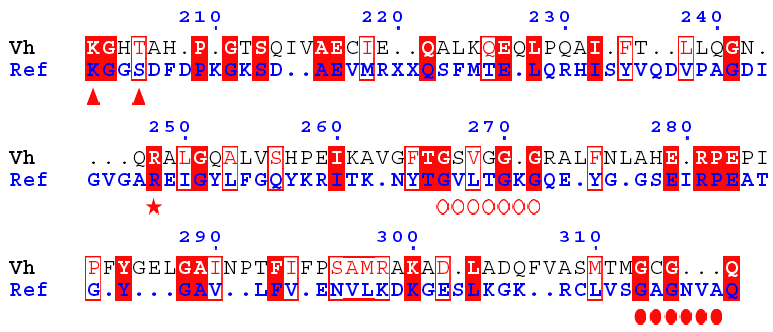
I. Search of a second NAD(P)H-binding site Aldehyde dehydrogenase from Vibrio harveyi is one of the most NADP-specific. The alignment of GDH from Ref and aldehyde DH shows that :
Therefore, the latter is likely a second nucleotide-binding motif specific of GDH4.
This figure was generated using the software ESpript. |
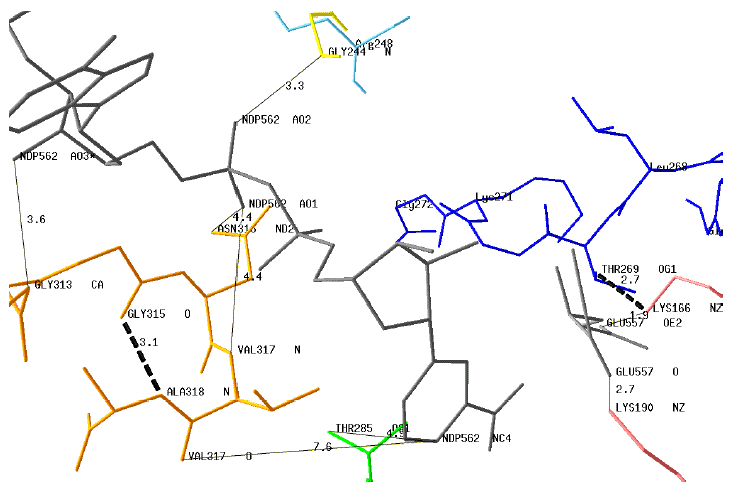
| K.
Modelisation of the dinucleotide-binding motives and key residues of
GDH4 with NADPH (NDP562) and Glu
A theoretical 3D structure of GDH4 from Ref was generated with the homology-modeling program ESyPred3D using as the template the structure of bovine GDH3 (PDB # 1HWZ). The modelisation and the drawing of a putative structure of GDH4 was performed with the protein structure homology-modeling program DeepView (SwissPdb-Viewer v. 3.7).
Some interactions (plain lines) between the motif G313AGNVA318 or key residues and the coenzyme are indicated : NDP562AO3 - Gly313CA; NDP562AO1 - Asn316ND2; NDP562AO1 - Val317N; NDP562AO2 - Gly244N; NDP562NC4 - Thr285OG1 The distances between the protonated carbon atom of the nicotinamide moiety (NDP562NC4) are too long for direct interactions with the motif G313AGNVA318. However, this motif is stabilized by an internal H-bond Gly315O - Ala318N (dotted line). Two distances (Glu557OE2 - Lys166NZ and Glu557O - Lys190NZ) are compatible with H-bond interactions between the enzyme and Glu. The position of the motif G266VLTGKG272 is shown with the potential H-bond Lys166NZ - Thr269OG1. |
![]()