| Les immunoglobulines et la recombinaison V(D)J |
| Tweet |
|
|
1. Introduction 2. Structure des immunoglobulines 3. Les classes ou isotypes d'immunoglobulines 4. Organisation et réarrangement des segments des gènes des immunoglobulines 5. La recombinaison V(D)J RSS et les protéines du complexe recombinase V(D)J
|
6. Le domaine d'interaction avec l'antigène
7. Liens Internet et références bibliographiques |
1. Introduction a. Les immunoglobulines Elles sont sécrétées par les plasmocytes (stade final de la différenciation des lymphocytes B). Elles constituent une super-famille de glycoprotéines solubles impliquées dans la reconnaissance et la fixation d'une substance étrangère appelée antigène ("antigen" est la contraction de "Antisomatogen + Immunkörperbildner") ou dans l'adhésion entre cellules. Quelques dates clés :
|
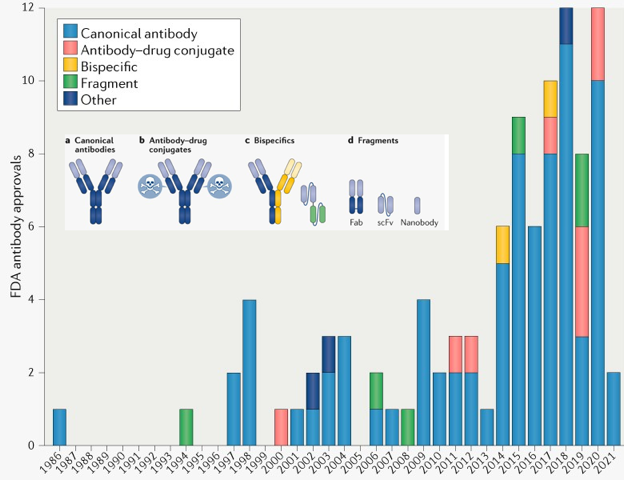
b. Les anticorps monoclonaux thérapeutiques Les termes anticorps et immunoglobuline sont souvent employés comme synonymes. Cependant, le terme anticorps est davantage réservé à la forme sécrétée et soluble des immunoglobulines car un anticorps ne possède pas de domaine trans-membrane plasmique. Les anticorps constituent donc le principal type d'immunoglobulines dans le sang. Ce sont des glycoprotéines synthétisées par le système immunitaire en présence d'un antigène.
Source : Mullard A. (2021) Les types d'anticorps monoclonaux thérapeutiques sont :
L'apparition de la COVID-19 se traduit par le développement de dizaines de médicaments ciblant le SRAS-CoV-2 et la protéine de pointe du virus est désormais l'une des dix premières cibles. Plusieurs produits ont obtenu une autorisation par la FDA pour une utilisation d'urgence, mais pas une approbation complète. |
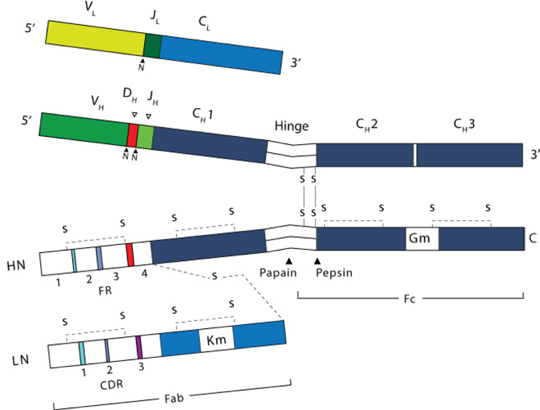
2. Structure des immunoglobulines Les immunoglobulines sont parmi les protéines dont on connaît le mieux la structure (des centaines de structure tridimensionnelles ont été déterminées). Voir "Antibody - Proteopedia". Cependant, ce sont des protéines très flexibles et la plupart des structures qui ont été obtenues concernent des fragments d'immunoglobulines. Exemples de structures d'immunoglobulines entières : 1IGT - 1IGY - 1HZH. a. Les chaînes des immunoglobulines Les immunoglobulines sont des protéines "tout-β" composées de :
Source : Schroeder & Cavacini (2010) |
|
b. Les régions des immunoglobulines Les chaînes polypeptidiques L et H possèdent :
Les régions V et C sont codées par des éléments indépendants : les segments de gènes V(D)J pour la région V et des exons pour les régions C. La séquence primaire de la région V est fonctionnellement divisée :
c. Les domaines des immunoglobulines Les chaînes L (κ ou λ) possèdent 2 domaines :
Les chaînes H possèdent 4 ou 5 domaines :
d. Paratopes, épitopes et idiotypes Les interactions immunoglobuline - antigène s'établissent entre :
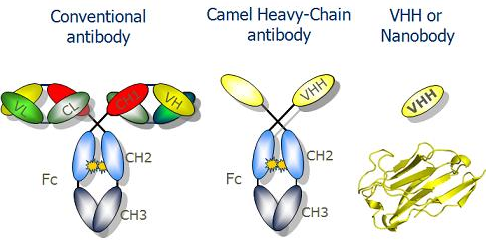
L'immunisation d'espèces hétérologues avec des anticorps monoclonaux a permis d'identifier les déterminants antigéniques individuels des immunoglobulines appelés idiotypes, qui sont contenus dans les régions V. e. La superfamille des immunoglobulines Les vertébrés et les invertébrés possèdent un grand nombre de protéines à la surface des cellules. Ces protéines sont étroitement apparentées et semblent avoir évolué à partir des séquences de gènes communs. Ces protéines forment la superfamille des immunoglobulines (qui incluent les récepteurs de surface et les molécules d'adhésion). Ces protéines contiennent toutes des domaines immunoglobulines (forte homologie de séquence en acides aminés et de structure tridimensionnelle avec des ponts disulfures intracaténaires). f. Les nano-anticorps ("nanobodies") Un sous-ensemble d'anticorps chez une minorité d'espèces [par exemple, les camélidés ou le requin nourrice] ne possèdent pas de chaînes L et n'ont que les chaînes H pour la liaison à l'antigène.
Source : Nanobody-aided crystallography Ces variants n'existent pas chez l'homme et il y a des tentatives pour "humaniser" ce type d'anticorps à des fins thérapeutiques et diagnostiques. Il s'agit des anticorps simple domaine ("single-domain antibody" ou "nanobody") qui correspondent seulement au domaine variable d'une chaîne H (VH). Ils ont une taille qui est environ 1/10ème de celle des immunoglobulines et une masse molaire de 12 à 15 kDa (environ 110 acides aminés), bien moindre que celle des anticorps communs (voir tableau ci-dessus). Récemment, l'équipe de Brian Kobilka (Prix Nobel de Chimie 2012) a conçu un fragment d'anticorps de haute affinité qui stabilise la conformation active de β2AR (β2-adrénocepteur). Les structures de β2AR lié à 3 agonistes chimiquement distincts ont ainsi été déterminées. |
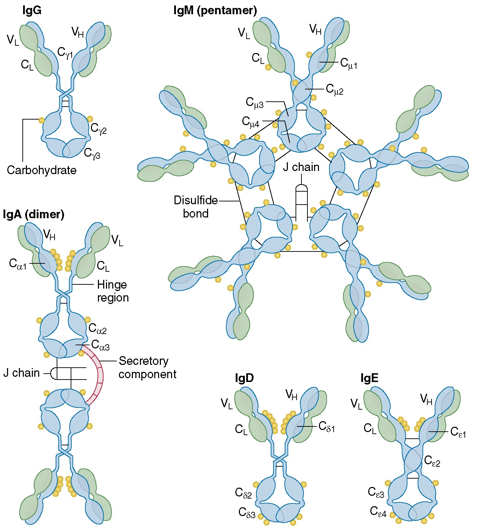
3. Les classes ou isotypes d'immunoglobulines Les régions constantes des chaînes polypeptidiques H possèdent une séquence d'acides aminés qui leur sont caractéristiques et qui permettent de définir 5 classes d'immunoglobulines (Ig) ou isotypes : IgM, IgD, IgG, IgE et IgA.
Source : J. Actor (2013) Il existe 4 sous-classes de l'isotype IgG : IgG1, IgG2, IgG3 et IgG4. Il existe 2 sous-classes de l'isotype IgA : IgA1 et IgA2. |
| Paramètre | Classe d'immunoglobuline (Ig) | ||||
| Isotype | IgM | IgD | IgG | IgE | IgA |
| Structure quaternaire (H = "heavy" - L = "light") |
Pentamère H10L10J |
Monomère H2L2 |
Monomère H2L2 |
Monomère H2L2 |
Monomère ou dimère H2L2 H4L4JSC |
| Appellation de la chaîne lourde (masse molaire - kDa) | μ (65) | δ (70) | γ (53) | ε (73) | α (55) |
| Masse molaire (kDa)a | 900 - 970 | 180 - 185 | 146 - 165 | 188 | 160 - 395 |
| Localisation | Lymphocyte B | Lymphocyte B | Sang | Basophiles - mastocytes | Muqueuses - sécrétions |
| Concentration dans le sérum (mg/mL)a | 0,5 - 2 | 0 - 0,4 | 0,5 - 16,0 | < 0,0001 | 0,5 - 4,0 |
| Proportion (%) | 10 | < 1 | 70 - 75 | < 1 | 15 - 20 |
| Temps de demie-vie dans le sérum (jours) | 5 - 10 | 3 | 7 - 23 | 2,5 | 6 |
| chaîne J | Oui | Non | Non | Non | Oui |
| Taux de glycosylation (% en poids) | 12 | 13 | 3 | 12 | 10 |
| Activation du complément | Fort | Non | Oui (sauf IgG4) | Non | Non |
| Neutralisation de toxines bactériennes | Oui | Non | Oui | Non | Oui |
| Activité anti-virale | Non | Non | Oui | Non | Oui |
| Fixation aux mastocytes ("mast cells") et aux basophiles | Non | Non | Non | Oui | Non |
| Autres propriétés | Anticorps intravasculaire produit très tôt dans la réponse immunitaire. Du fait de son haut degré oligomèrique, il est très efficace comme agglutinateur des bactéries et des antigènes particulaires. Efficace pour l'opsonisation des bactéries. |
Trouvées à la surface des lymphocytes B matures. Elles fonctionnent avec les IgM. |
Anticorps dépendant de la cytotoxicité de la cellule. Immunoglobulines les plus abondantes dans les fluides extravasculaires. Elles neutralisent les toxines et les micro-organismes en activant le système du complément et en facilitant la liaison des cellules phagocytaires. |
Responsables des symptômes d'allergie atopique comme l'eczéma et l'asthme. Efficace contre les vers parasites. Elles se lient aux mastocytes et, au contact de l'antigène, recrutent des agents antimicrobiens via la dégranulation des mastocytes et la libération de médiateurs inflammatoires. |
Sous forme de monomère dans les sécrétions et de dimère à la surface épithéliale. |
| aLes chiffres varient d'une source à l'autre. L'opsonisation est la fonction du système immunitaire qui tapisse par l'opsonine la membrane externe des cellules qui doivent être détruites. |
|||||
| Paramètre | IgG1 | IgG2 | IgG3 | IgG4 |
| % des IgG totales | 70 | 20 | 7 | 3 |
| Temps de demie-vie (jours) | 23 | 23 | 7 | 23 |
| Fixation au complément | + | + | Fort | Non |
| Passage dans le placenta | ++ | ± | ++ | ++ |
| Fixation au monocytes | Fort | + | Fort | ± |
4. Organisation et réarrangement des segments des gènes des immunoglobulines a. Origine de la diversité des immunoglobulines Les immunoglobulines doivent reconnaître spécifiquement un nombre extrêmement élevé de peptides antigèniques. Un mécanisme, appelé recombinaison V(D)J, permet d'obtenir cette diversité des immunoglobulines. Cette recombinaison est catalysée par un complexe protéique appelé recombinase V(D)J. La recombinaison V(D)J s'effectue pour les gènes codant la région V des chaînes L et les gènes codant la région V des chaînes H qui sont organisés en segments distincts dénommés :
Chaque segment de gène V contient généralement :
Chaque segment de gène J contient généralement :
|
|
Nombre de segments de gènes V, D et J et d'exons C fonctionnels dans les loci immunoglobulines chez l'homme Les chiffres varient selon l'haplotype de l'individu. |
|||
Chaînes L |
Chaîne H | ||
| Segment ou exon | Chaîne κ locus IGK - chromosome 2 homme (2p11.2) |
Chaîne λ locus IGL - chromosome 22 homme (22q11.2) |
locus IGH - chromosome 14 homme (14q32.33 ) |
| Variable (V) | 40 - 75 Vκ : 30 sont fonctionnels | 30 - 36 Vλ | environ 80 VH : 39 sont fonctionnels |
| Diversity (D) | 0 Dκ | 0 Dλ | 27 DH |
| Joining (J) | 5 Jκ | 4 Jλ | 6 JH |
| exon (C) | 1 Cκ | 4 Cλ | 9 CH : 1 µ (IgM), 1 δ (IgD), 4 γ (IgG) 1 ε (IgE), 2 α (IgA) |
|
Nombre minimal théorique d'immunoglobulines |
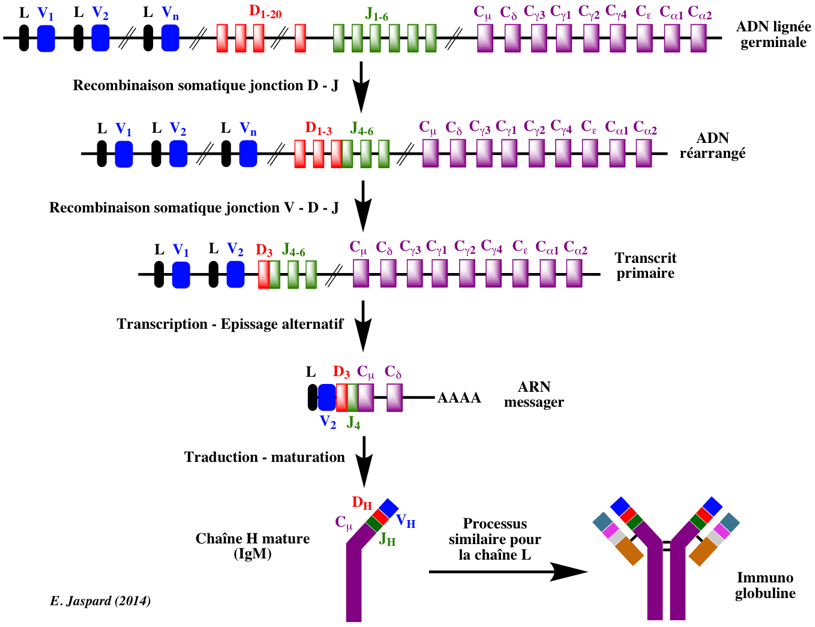
Figure ci-dessous : réarrangement des segments de gènes codant les chaînes H des immunoglobulines.
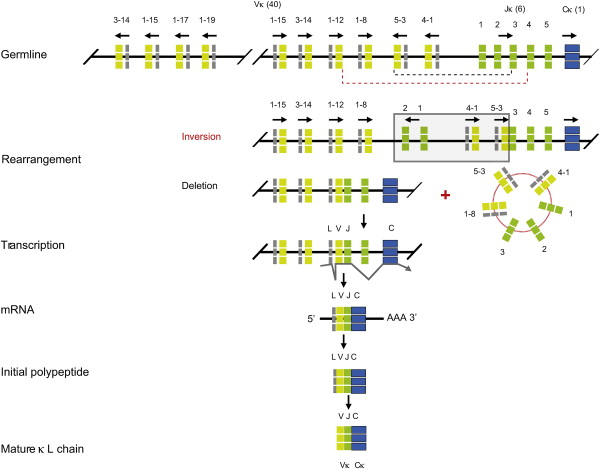
Le processus est le même pour les chaînes L. Le complexe protéique recombinase V(D)J catalyse la jonction de différents segments de gènes VH, DH et JH (étapes de recombinaison somatique). Puis l'épissage alternatif joint les séquences V(D)J réarrangées à des exons codant la région CH. Puis l'isotype d'immunoglobuline est synthétisé. Voir "Mécanisme du réarrangement". b. Réarrangement du locus de la chaîne L Chez l'homme (et la plupart des autres mammifères), il y a 2 loci de chaîne L (κ ou λ) situés sur les chromosomes 2 et 22, respectivement. Le réarrangement des gènes codant les chaînes L des immunoglobulines est semblable à celui du locus de la chaîne H, mais il n'y a pas de segment de gène D. De plus, il n'y a qu'1 région constante pour le locus κ, tandis que le locus λ possède plusieurs régions constantes, chacune avec son propre segment de gène J. Figure ci-dessous : réarrangements génétiques et maturation du transcrit débouchant sur la synthèse de la chaîne L (κ) mature chez l'homme.
Source : Schroeder & Cavacini (2010) |
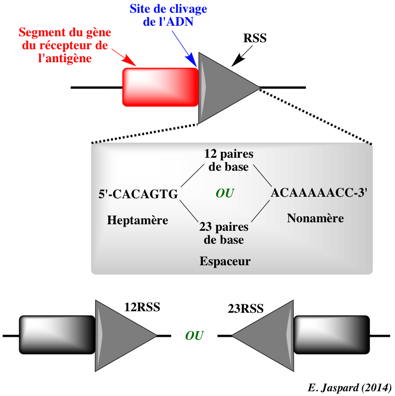
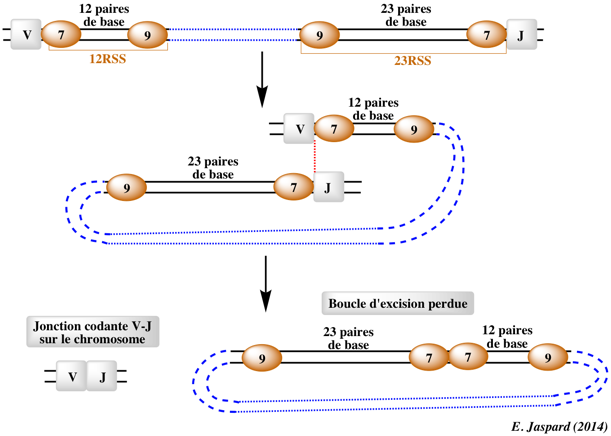
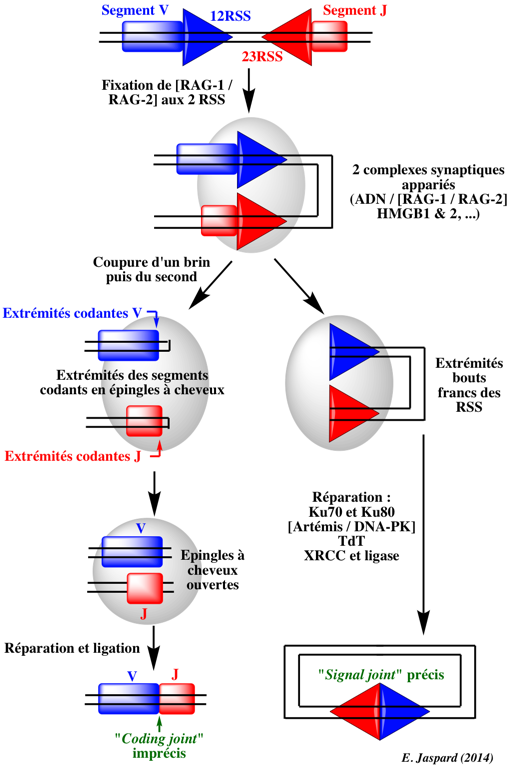
α. Phase de reconnaissance des RSS et de coupure de l'ADN
Ce processus est facilité par l'action des protéines HMGB1 ("High-Mobility Group protein B1") et HMGB2 qui courbent l'ADN et contribuent au rapprochement des 2 RSS. La coupure de l'ADN par le complexe [RAG-1 / RAG-2] (voir le mécanisme) génère :
Les extrémités en épingle à cheveux sont de nouveau coupées, ce qui crée une extrémité 3′ débordante qui est complétée par l'ADN polymérase ou clivée ou modifiée par addition de nucléotides, pendant la phase de réparation. β. Phase de réparation Les extrémités coupées du segment de gène codant sont réparées par un ensemble de protéines impliquées dans le processus de réparation de l'ADN de type "NonHomologous End-Joining" (NHEJ). Ces protéines sont (entre autres) :
Par ailleurs, avant que les segments V et D ne soient joints pour restaurer l'intégrité du chromosome, les extrémités 3' contiennent une séquence palindrome ajoutée à la séquence du segment et qui résulte de la coupure par RAG-1 : ces quelques nucléotides sont appelés P-nucléotides (pour "Palindromic sequences").
Ces délétions ou additions de nucléotides contribuent à l'hypervariabilité des séquences CDR3. |
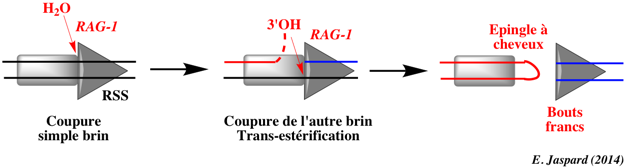
γ. Mécanisme de clivage de l'ADN par RAG-1 Le complexe [RAG-1 / RAG-2] coupe un brin de l'ADN immédiatement en amont de la séquence heptamère, ce qui génère un groupe hydroxyle en 3'. Ce groupe attaque la liaison phosphodiester sur l'autre brin par une réaction de trans-estérification directe.
Ce processus génère 2 types d'extrémités de l'ADN :
δ. Diversité des immunoglobulines Il est maintenant évident que, malgré la règle "12 - 23", des jonctions [D-D] se produisent chez la plupart des espèces (5% des anticorps chez l'homme). C'est même le mécanisme à l'origine des boucles CDR3 inhabituellement longues de certaines chaînes H. Ces CDR3 extra-longues et les combinaisons inhabituelles d'acides aminés qui en résultent contribuent à la diversité du répertoire des anticorps. Par ailleurs, la combinaison :
confère une diversité extrême des séquences des gènes codant les anticorps des lymphocytes B et les récepteurs des lymphocytes T qui en résultent. Ainsi, on estime le nombre d'immunoglobulines à 1011 - 1012 et des chiffres tels que 1013 - 1016 sont mentionnés dans la littérature. Cette stupéfiante diversité des séquences des gènes permet au système immunitaire d'apporter une réponse contre pratiquement n'importe quel antigène étranger. |
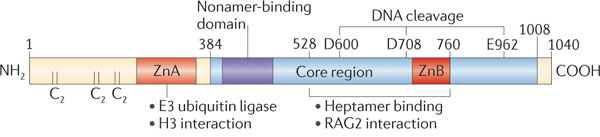
c. Les protéines RAG-1 et RAG-2 RAG1 ("V(D)J recombination-activating protein 1") est le composant catalytique du complexe [RAG-1 / RAG-2] qui coupe l'ADN au cours de la recombinaison V(D)J. Cette enzyme possède :
Le site actif de RAG-1 (384 - 1008) contient 3 acides aminés acides (D600, D708 et E962 - motif DDE) essentiels pour la coupure du brin d'ADN et pour la formation de la structure en épingle à cheveux. RAG-1 forme un homodimère symétrique lié à 2 molécules d'ADN : chaque sous-unité du dimère interagit avec les deux molécules d'ADN. Les hélices 2 (426 - 441) et 3 (444 - 454) des NBD des deux monomères forment un faisceau de 4 hélices qui constitue l'interface du dimère.
Source : Schatz & Ji (2011)
Les interactions [RAG-1 - ADN] s'établissent essentiellement avec la séquence nonamère et l'espaceur et impliquent de nombreux contacts avec le squelette phosphodiester :
|
|
Visualisation du complexe entre le domaine de fixation de la séquence nonamère de RAG-1 de Mus musculus et l'ADN. Les acides aminés 389-456 de NBD sont représentés. Code PDB : 3GNA
|
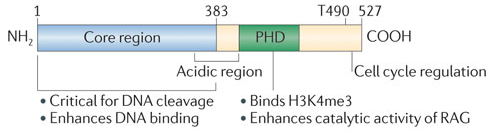
RAG-2 ("V(D)J recombination-activating protein 2") n'est pas un composant catalytique mais il est nécessaire pour l'activité catalytique : il augmente l'affinité du domaine NBD de RAG-1 pour les séquences reconnues et c'est un cofacteur essentiel pour le clivage de l'ADN.
Source : Schatz & Ji (2011) La structure de la chromatine joue un rôle essentiel dans la recombinaison V(D)J. En effet, le domaine C-terminal de RAG-2 (acides aminés 384 à 527) contient un motif "plant homeodomain (PHD) finger" qui se fixe spécifiquement sur l'histone H3 triméthylée sur Lys4 (H3K4me3), ce qui stimule l'activité catalytique du complexe [RAG-1 / RAG-2] et guide RAG-2 vers les régions actives de la chromatine. |
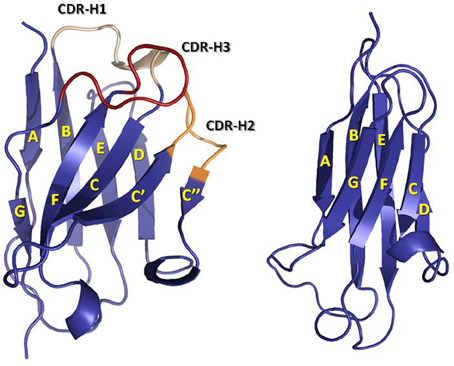
6. Le domaine d'interaction avec l'antigène a. Structure des domaines V des chaînes L et H Les domaines V et C ont une structure semblable et adoptent un repliement typique de la superfamille des immunoglobulines ("Ig fold") : 2 feuillets β (chacun étant constitués de brins β anti-parallèles) compactés ensemble (repliement de type "sandwich β").
Source : Finlay & Almagro (2012)
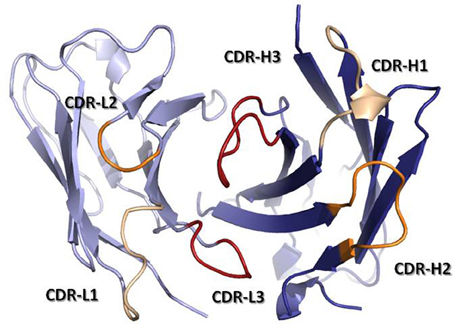
Les domaines V et C sont tout deux stabilisés par un pont disulfure intra-domaine (Cys βB - Cys βF). Le domaine V est cependant moins compact que le domaine C car il possède 3 boucles (qui relient les brins des feuillets β) plus longues (donc plus flexibles) dont les séquences sont hypervariables. Ces boucles, appelés régions déterminant la complémentarité ("Complementarity Determining Regions" - CDR), constituent la région principale du site de fixation de l'antigène (ou paratope).
Source : Finlay & Almagro (2012) Chaque domaine V apporte 3 CDR au site de fixation de l'antigène :
Rappel :
Modèles de numérotation standardisée des CDR :
|
|
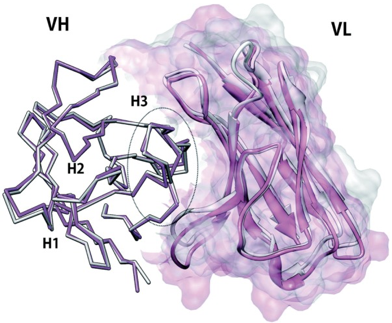
b. Nombre restreint des conformations des CDR - conception d'anticorps artificiels Paradoxalement, bien que reconnaissant un nombre colossal de structures d'antigènes, 5 CDR [CDR-L1, CDR-L2, CDR-L3, CDR-H1 et CDR-H2] adoptent un nombre très restreint de conformations (appelées "structures canoniques") qui sont déterminées par la longueur des boucles hypervariables et les acides aminés conservés dans les CDR (mais aussi les FR). Le nombre de conformations est plus grand pour la chaîne L(λ) que la chaîne L(κ). Par exemple :
Une telle variabilité de composition et de longueur (donc de flexibilité) rend difficile la modélisation de la boucle CDR-H3. Cependant, la bioinformatique, la mécanique moléculaire et la détermination d'un nombre croissant de structures tri-dimensionnelles permettent d'établir des règles pour la prédiction des CDR (voir aussi : "H3-rule").
Source : Kuroda et al. (2012) Il est donc capital de :
pour la conception d'anticorps artificiels par modélisation moléculaire ("computational methods", "in silico antibody designs - drug discovery").
Source : Kuroda et al. (2012) - Remarque : L signifie chaîne L (et non pas leucine) / H signifie chaîne H (et non pas histidine). |
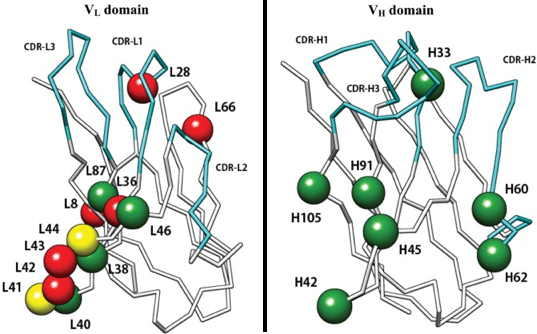
Le nombre restreint de conformations adoptées par les CDR résulte du petit nombre d'acides aminés différents à des positions clés dans les CDR et les FR.
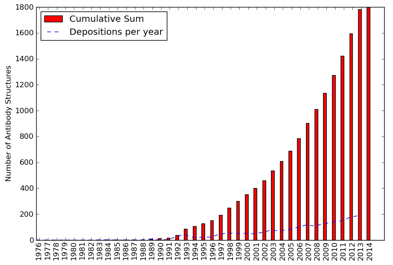
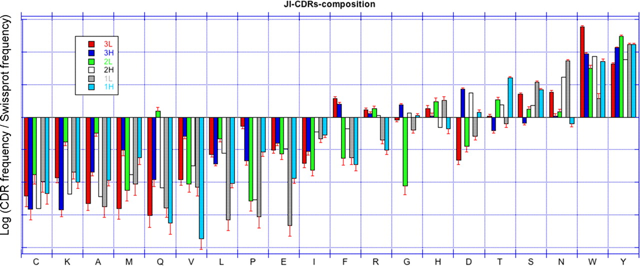
Source : SAbDab Une étude des contacts au sein de complexes [anticorps - antigène] à partir des données structurales (environ 1800 structures d'anticorps dans la PDB en 2014 - figure ci-dessus) a montré que :
Source : Ofran et al. (2008) La figure ci-dessus montre la sous-représentation et la sur-représentation des acides aminés dans les CDR (par rapport à leur fréquence dans toutes les protéines). Caractéristiques des épitopes des lymphocytes B :
|
| 7. Liens Internet et références bibliographiques |
|
"Animation Quiz 2 - Antibody Diversity" "Immunobiology: The Immune System in Health and Disease - 5th ed." "IMGT : the international ImMunoGeneTics information system" |
|
|
Schroeder & Cavacini (2010) "Structure and function of immunoglobulins" J. Allergy Clin. Immunol. 125, S41 - S52 Schatz & Ji (2011) "Recombination centres and the orchestration of V(D)J recombination" Nat. Rev. Immunol. 11, 251-263 |
|
|
J. Actor (2013) "Antibody Structure and Function" Elsevier's Integrated Review: Immunology and Microbiology 2nd Ed. Pantazes & Maranas (2013) "MAPs: a database of modular antibody parts for predicting tertiary structures and designing affinity matured antibodies" BMC Bioinformatics 14, 168 |
|
|
Schatz & Swanson (2011) "V(D)J recombination: mechanisms of initiation" Annu. Rev. Genet. 45, 167 - 202 Nishana & Raghavan (2012) "Role of recombination activating genes in the generation of antigen receptor diversity and beyond" Immunology 137, 271 - 281 Coussens et al. (2013) "Acidic Hinge Restricts Repair-Pathway Choice and Promotes Genomic Stability" Cell Reports 4, 870 - 878 |
|
|
Ofran et al. (2008) "Automated identification of complementarity determining regions (CDRs) reveals peculiar characteristics of CDRs and B cell epitopes" J. Immunol. 181, 6230 - 6235 Finlay & Almagro (2012) "Natural and man-made V-gene repertoires for antibody discovery" Front. Immunol. 3, 342 |
|
|
Kuroda et al. (2008) "Structural classification of CDR-H3 revisited: a lesson in antibody modeling" Proteins 73, 608 - 620 Chailyan et al. (2011) "Structural repertoire of immunoglobulin λ light chains" Proteins 79, 1513 - 1524 Kuroda et al. (2012) "Computer-aided antibody design" Protein Eng. Des. Sel. 25, 507 - 522 |
|
|
Kabat et al. (1983) "Sequence of Proteins of Immunological Interest" Bethesda: National Institute of Health Al-Lazikani et al. (1997) "Standard conformations for the canonical structures of immunoglobulins" J. Mol. Biol. 273, 927 - 48 Lefranc et al. (2003) "IMGT unique numbering for immunoglobulin and T cell receptor variable domains and Ig superfamily V-like domains" Dev. Comp. Immunol. 27, 55 - 77 |
|
|
"SAbDab : The Structural Antibody Database" "The AAAAA aims to become the ultimate tool for antibody structural analysis, modelling and engineering" "Abysis : The Abysis database integrates sequence data from Kabat, IMGT and the PDB with structural data from the PDB" |
|
|
Zhang et al. (2019) "The fundamental role of chromatin loop extrusion in physiological V(D)J recombination" Nature 573, 600 - 604 Zhang et al. (2019) "Fundamental roles of chromatin loop extrusion in antibody class switching" Nature doi:10.1038/s41586-019-1723-0 Mullard A. (2021) "FDA approves 100th monoclonal antibody product" Nat. Rev. Drug Discov. 20, 491 - 495 |
|
![]()