
| Les facteurs de transcription |
| Tweet |
|
|
1. Introduction
2. Classification des facteurs de transcription 3. Les facteurs de transcription généraux 4. Les structures des domaines de fixation de l'ADN des facteurs de transcription
|
5. Les récepteurs nucléaires
6. Quelques exemples de familles de facteurs de transcription de plantes et d'animaux liés aux stress biotiques et abiotiques 7. Liens Internet et références bibliographiques |
1. Introduction Un facteur de transcription (FT) est une protéine qui se fixe sur une séquence spécifique de l'ADN. Il contrôle le flux (la vitesse) de la transcription d'un gène. Les FT régulent la transcription seul ou sous forme de complexe avec d'autres protéines : ils activent ou inhibent le recrutement de l'ARN polymérase sur des gènes spécifiques. Les FT sont présent chez tous les organismes vivants. Leur nombre est corrélé à la taille du génome d'un organisme. Le génome de l'homme code au moins 2600 protéines possédant un domaine de fixation de l'ADN (environ 10% des gènes). Les FT constituent la famille de protéines la plus vaste. Du point de vue structural, les FT possèdent un ou plusieurs domaine(s) de fixation à l'ADN qui se fixent à une séquence spécifique régulatrice de l'ADN [amplificateur ("enhancer") ou promoteur ("promoter")] adjacente aux gènes que les FT régulent. Les FT régulent la transcription via différents mécanismes :
Exemples de techniques pour étudier l'interaction protéine - ADN
|
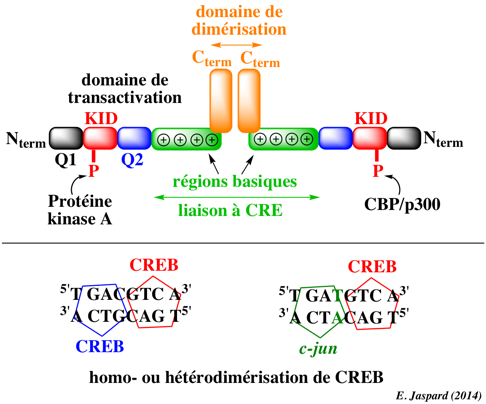
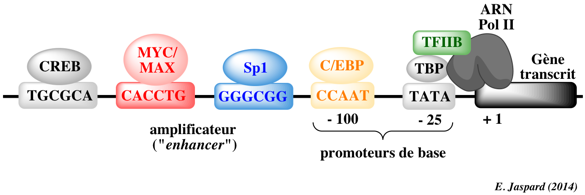
a. Les séquences appelées éléments de réponse Pour que la transcription ait lieu, l'ARN polymérase (enzyme qui synthétise l'ARN) doit se fixer à l'ADN près d'un gène. Les régions de l'ADN appelées promoteurs contiennent des séquences d'ADN spécifiques et des éléments de réponse ("response elements") qui sont un site sûr de fixation initiale de l'ARN polymérase et des FT qui recrutent l'ARN polymérase. La boîte CCAAT (ou boîte CAAT ou boîte CAT) est une séquence consensus [GGCCAATCT] qui se situe 75 à 80 paires de base en amont du site initial de la transcription. La boîte CAAT est un site signal de fixation des FT. Illustration : signalisation par l'AMPc - CRE, CREB et CBP Les éléments de réponse à l'AMPc appelés CRE ("cAMP Responsive Elements") sont des séquences nucléotidiques consensus qui se situent dans la partie régulatrice des gènes dont la transcription est dépendante de la présence de l'AMP cyclique (AMPc). CRE est un "enhancer" (voir ci-dessous) et se trouve 100 à 150 paires de base en amont de la boîte TATA. La plupart des gènes dont la transcription est dépendante de l'AMPc contiennent une séquence palindromique 5'-TGACGTCA-3' ou une partie de cette séquence (5'-CGTCA-3'). Les protéines de liaison à CRE sont appelées CREB ("CRE Binding protein") : ce sont des facteurs de transcription de type "leucine-zipper" (voir ci-dessous). Les CREB forment des homodimères ou des hétérodimères avec un autre facteur de transcription (exemple : c-jun). L'affinité des dimères CREB pour CRE est élevée (Kd = 1 nM). CREB contient un domaine transactivateur constitué :
Figure inspirée de "Communications et signalisations cellulaires" Y. Combarnous (2004) La fixation aux sites CRE dépend des séquences qui flanquent la séquence promoteur. Si ces séquences contiennent des sites de fixation pour d'autres facteurs de transcription (et qu'ils sont présents), les interactions entre CREB et les autres facteurs de transcription favorisent la formation de complexe ternaire [ADN-CREB-autreFT]. L'existence de tels complexes dans des compartiments ou cellules diverses et à des moments différents jouent un rôle important dans le contrôle spatio-temporel de la transcription des gènes contrôlés par l'AMPc. L'étape de transactivation est stimulée par la phosphorylation par la protéine kinase A. L'état phosphorylé ou non de CREB n'influence ni sa dimérisation ni sa fixation à l'ADN. La phosphorylation ne semble requise que pour le recrutement de son co-activateur : la protéine CBP ("CREB Binding Protein"). La phosphorylation de Ser133 du domaine KID de CREB induit son activation : CREB change de conformation et interagit avec le domaine KIX de CBP (ou de son paralogue p300). CBP agit comme "échaffaudage" pour l'ensemble des molécules impliquées dans la transcription. Son interaction avec les FT spécifiques liés à leurs éléments de réponse au niveau du promoteur permet son interaction avec différents FT généraux (voir ci-dessous) tels que TBP ("TATA box Binding Protein" - composant de TFIID), TFIIB, TFIIE et TFIIF. CBP participe donc à la formation et à la stabilisation du complexe actif nécessaire pour la transcription par l'ARN polymérase II appelé complexe d'initiation de la transcription. CBP possède une activité histones-acétylase sur des lysines de l'extrémité N-terminale des histones. Cette acétylation induit la déstabilisation des nucléosomes et permet le passage de l'ARN polymérase. CBP recrute des protéines appelées "Nucleosome Assembly Proteins" impliquées dans le contrôle de l'organisation des réseaux de nucléosomes formant la chromatine. |
| Elements de réponse ("Response element" - RE) | |||||
| Agent régulateur | Module | Séquence consensus | paires de bases d'ADN fixées | Facteur | Masse molaire (Da) |
| Choc thermique | HSE | CNNGAANNTCCNNG | 27 bp | HSTF | 93,000 |
| Glucocorticoide | GRE | TGGTACAAATGTTCT | 20 bp | Receptor | 94,000 |
| Cadmium | MRE | CGNCCCGGNCNC | -------- | ? | -------- |
| Ester de phorbol | TRE | TGACTCA | 22 bp | AP1 | 39,000 |
| Sérum | SRE | CCATATTAGG | 20 bp | SRF | 52,000 |
| Anti-oxydant | ARE | GTGACTCAGC | -------- | -------- | -------- |
| Phéromone | ACAAAGGGA | -------- | -------- | -------- | |
| Hypoxie | HRE | CCACAGTGCATACGT GGGCTCCAACAGGTC CTCTCCCTCCCATGCA |
-------- | "Hypoxia Inducible Factor" | 826 aa |
| "Peroxisome Proliferator Activated Receptor" (PPAR) | PPRE | aGG_CAAAGGT(CG)A | -------- | PPAR | 59,000 |
| Stéroides (progèsterone, androgène, minéralcorticoides, glucocorticoides) | AGAACAxxxACAAGA |
-------- | -------- | -------- | |
Eléments agissant en "cis" (action d'une molécule sur elle-même) : séquences consensus de l'ADN située en amont des sites d'initiation de la transcription. Exemple : l'opéron lac. PLACE : "A Database of Plant Cis-acting Regulatory DNA Elements" |
||
| Procaryotes | région -10 ou boîte
Pribnow - Schaller (10 nucléotides avant le site d'initiation de la transcription) |
Séquence consensus : TATAAT |
| Eucaryotes - Archaea | région -10 ou boîte Goldberg - Hogness ou "TATA box" | TATAAT |
| Eléments agissant en "trans" (action d'une molécule sur une autre) : ce sont les facteurs de transcription (protéines) qui se fixent sur ces séquences d'ADN (les éléments agissant en "cis") . | ||
b. Quelques définitions : promoteur, activateur, enhancer, répresseur, opérateur, silencer, insulator Une séquence amplificatrice ("enhancer") est une région de l'ADN (de 50 à 1500 paires de bases) sur laquelle se fixent les FT pour activer la transcription de gène(s). Les "enhancers" sont des éléments agissant en cis ("cis-acting elements") qui peuvent se situer jusqu'à 1 million de paires de bases (en amont ou en aval) des gènes régulés. Il existe des centaines de milliers de "enhancers" dans le génome humain. Les protéines qui, en se fixant sur un promoteur de l'ADN (exemple : les FT) ou en participant à la fixation d'autres protéines sur un promoteur de l'ADN, activent la transcription de gène(s) sont appelées globalement activateurs. Exemple : La protéine "Catabolite Activator Protein" - CAP (ou "cAMP Receptor Protein") active la transcription de l'opéron lac chez Escherichia coli. Une séquence opérateur est une région de l'ADN qui est proche d'un promoteur (voire qui la recouvre en partie) et sur laquelle se fixe un répresseur.
Les séquences appelées "insulator" ("isolant") empêche un "enhancer" (ou un "silencer") d'activer (ou d'inhiber) la transcription d'un autre gène voisin. Ces séquences se situent entre un "enhancer" (ou un "silencer") et le promoteur. Les "insulator" des Eucaryotes ont une séquence de nucléotides CCCTC sur laquelle se fixent des protéines appelées facteurs de fixation à CCCTC ("CCCTC-Binding Factor" - CTCF). Il existe d'autres séquences régulatrices sur lesquelles se fixent différents FT. Elles sont principalement situées en amont (5') du site d'initiation de la transcription, mais quelques unes sont en aval (3') voire au sein de la séquence du gène. Différentes combinaisons de FT ont des effets régulateurs différents sur l'initiation de la transcription. Chaque type de cellule possèdent des combinaisons de FT qui lui sont caractéristiques et qui contribuent dans une large mesure au phénotype de cette cellule. |
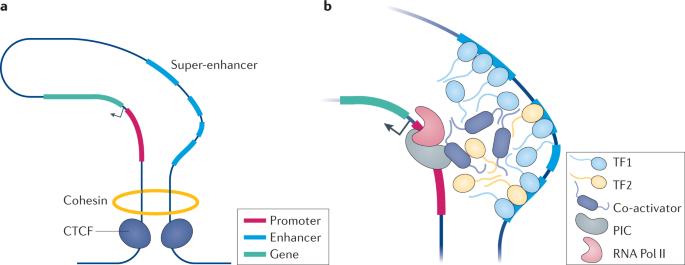
Illustration Figure (a) ci-dessous. Représentation du domaine associé topologiquement ("Topologically Associated Domain" - TAD) sur lequel sont fixées la cohésine et le CTCF. Le CTCF est une protéine à 11 doigts de zinc hautement conservée. C'est une protéine clé du contrôle de l'activation transcriptionnelle d'un gène qui peut fonctionner comme un activateur transcriptionnel, un répresseur ou un "insulator" en bloquant la communication entre les "enhancers" et les promoteurs.
Source : Henley & Koehler (2021) Figure (b) ci-dessus. Vue agrandie du modèle de séparation de phases lors de l'activation transcriptionnelle : les facteurs de transcription (TF1, TF2, ...) et les co-activateurs forment des condensats transcriptionnels qui recouvrent l'"enhancer" et le promoteur. PIC : complexe de pré-initiation ; RNA Pol II : ARN polymérase II. |
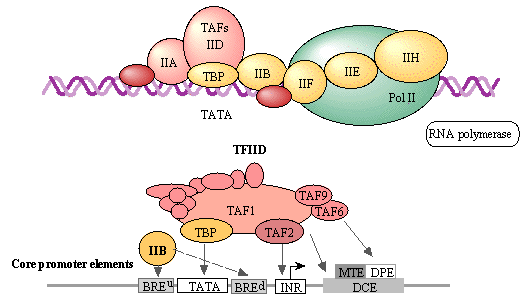
c. Les facteurs de transcription généraux C'est une classe majeure de FT chez les Eucaryotes dont un grand nombre ne se fixent pas à l'ADN mais font partie du complexe de pré-initiation qui interagit directement avec l'ARN polymérase II. Les facteurs de transcription généraux les plus courants sont TFIIA, TFIIB, TFIID, TFIIE, TFIIF et TFIIH (TFII : "Transcription Factors regulating RNA pol II"). Figure ci-dessous : "Basal transcription factors" (KEGG). La figure originale est interactive et permet d'obtenir un très grand nombre d'informations.
Le FT général TFIID se fixe sur la "TATA-box" (il est aussi appelé "TATA-box Binding Protein" - TBP).
La séquence consensus "CCAAT-box" (GG[T/C]CAATCT) se situe 50 à 130 paires de bases en amont du site d'initiation de la transcription. La protéine C/EBP ("CCAAT-box/Enhancer Binding Protein") se fixe sur cette séquence. CREB = "cAMP Response Element Binding protein". |
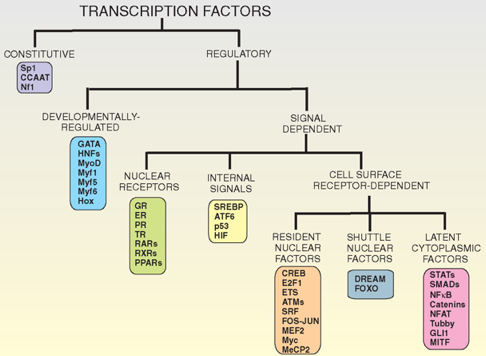
2. Classification des facteurs de transcription Il existe des centaines de FT.
Source : "Cell signaling biology" - Module 4 A. Certains FT sont toujours présents dans le noyau et actifs constitutivement. B. Les FT dont l'activité est régulée se divisent en 2 groupes :
C. Les FT dont l'activité dépend de signaux sont eux-mêmes subdivisés :
D. Les FT dont l'activité dépend les récepteurs de surface de la cellule sont eux-mêmes subdivisés :
|
| Exemple de classification des facteurs de transcription chez l'homme | |||
| Superclasse | Classe | Superclasse | Classe |
| 1 Basic domains | 1.1 Basic leucine zipper factors (bZIP) |
6 Immunoglobulin fold | 6.1 Rel homology region (RHR) factors 6.2 STAT domain factors 6.3 p53 domain factors 6.4 Runt domain factors 6.5 T-Box factors 6.6 NDT80 domain factors 6.7 Grainyhead domain factors |
| 2 Zinc-coordinating DNA-binding domains | 2.1 Nuclear receptors with C4 zinc fingers |
7 beta-Hairpin exposed by an alpha/beta-scaffold | 7.1 SMAD/NF-1 DNA-binding domain factors 7.2 GCM domain factors |
| 3 Helix-turn-helix domains | 3.1 Homeo domain factors 3.2 Paired box factors 3.3 Fork head / winged helix factors 3.4 Heat shock factors 3.5 Tryptophan cluster factors 3.6 TEA domain factors 3.7 ARID domain factors |
8 beta-Sheet binding to DNA | 8.1 TATA-binding proteins 8.2 A.T hook factors |
| 4 Other all-alpha-helical DNA-binding domains | 4.1 High-mobility group (HMG) domain factors |
9 beta-Barrel DNA-binding domains | 9.1 Cold-shock domain factors |
| 5 alpha-Helices exposed by beta-structures | 5.1 MADS box factors 5.2 E2-related factors 5.3 SAND domain factors |
0 Yet undefined DNA-binding domains | 0.1 AXUD/CSRNP domain factors 0.2 NonO domain factors 0.3 Leucine-rich repeat flightless-interacting proteins 0.4 NFX1-type putative zinc finger factors 0.0 Uncharacterized |
| Exemple de la sous-classification de la super classe "Basic domains" | ||
1.1 Basic leucine zipper factors (bZIP) 1.1.1 Jun-related factors |
1.2 Basic helix-loop-helix factors (bHLH) 1.2.1 E2A-related factors |
1.3 Basic helix-span-helix factors (bHSH) 1.3.1 AP-2 |
3. Les facteurs de transcription généraux ("General Transcription Factors") L'initiation de la transcription est plus complexe chez les Eucaryotes car les ARN polymérases ne reconnaissent pas directement leurs séquences promotrices : 5 facteurs de transcription généraux ("General Transcription Factor" : TFII-B, TFII-D, TFII-E, TFII-F et TFII-H) doivent d'abord médier la fixation des ARN polymérases et l'initiation de la transcription. Le complexe complet [ARN polymérase - facteurs de transcription - séquence ADN du promoteur] est appelé complexe de pré-initiation de la transcription. Ce complexe assure :
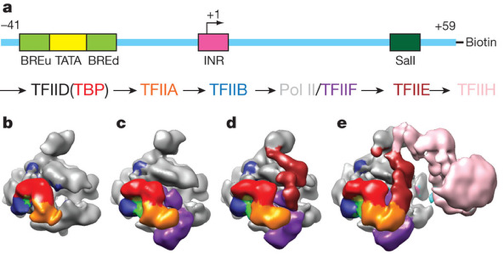
Cependant, certains mécanismes moléculaires et certaines fonctions de ce complexe sont encore inconnus, notamment par manque d'informations structuralles en raison de la taille gigantesque du complexe de pré-initiation (2 millions Da). En 2013, un système a été reconstitué in vitro pour étudier, par cryo-microscopie électronique, l'assemblage progressif de TBP ("TATA-Binding Protein"), Pol II et des facteurs de transcription généraux (TFIIA, TFIIB, TFIIF, TFIIE et TFIIH) sur un promoteur. Stratégie de reconstruction du complexe de pré-initiation humain par assemblage séquentiel.
Source : He et al. (2013) (a) : schéma de l'ADN mentionnant les positions relatives des éléments fondamentaux du promoteur utilisé et du site de restriction SalI. (b) à (e) : intermédiaires de l'assemblage du complexe de pré-initiation [TBP - TFIIA - TFIIB - ADN - Pol II] (b) puis addition de TFIIF (c) puis addition de TFIIE (d) puis addition de TFIIH (e). Les modèles obtenus à différentes étapes de l'initiation de la transcription décrivent les interactions entre les molécules de ce complexe :
|
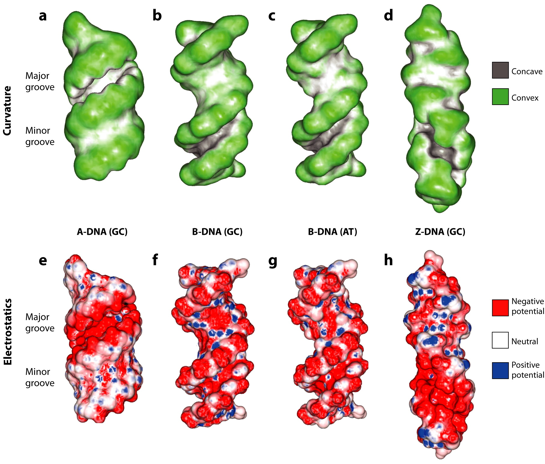
4. Les structures des domaines de fixation de l'ADN des facteurs de transcription a. Les différentes structures de l'ADN La "lecture directe" (ou "lecture de base") est un mécanisme de reconnaissance où les FT discriminent différentes bases dans une séquence d'ADN par l'intermédiaire d'interactions directes (ou médiées par l'eau) avec les bases de l'ADN. La "lecture indirecte" (ou "lecture de forme") est un mécanisme où les FT discriminent en fonction de la déformabilité de la séquence d'ADN ou des différences structurales des molécules d'ADN. Rappels sur les différents types de structure de l'ADN
Source : Rohs et al. (2010) Figures a et e : l'ADN de type A (séquence alternée d(GC)7) a un grand sillon profond (9,5 Å), étroit (2,2 Å) et fortement négatif et un petit sillon large (10,9 Å), peu profond avec une surface hydrophobe partiellement due aux C3′ des désoxyriboses qui sont exposés. Figures b, c et f : l'ADN de type B (séquence alternée d(GC)7) a un grand sillon large (11,4 Å), peu profond (4,0 Å) et assez peu négatif et un petit sillon étroit (5,9 Å), profond (5,5 Å) et négatif. Figures d et h : l'ADN de type Z (séquence alternée d(GC)7) n'a pas de grand sillon (largeur 13,2 Å et pas de profondeur définie) et une surface positive sur les faces opposés des bases et un petit sillon étroit (2,4 Å), profond (5,0 Å) et négatif. Figure g : séquence alternée d(AT)7) d'ADN de type B qui montre les différences de potentiel électrostatique entre GC et AT. Par exemple : groupe amino positif de la guanine dans le petit sillon GC et groupe méthyle neutre de la thymine dans le grand sillon AT. |
| Superfamille classification SCOP | Architecture du domaine de fixation de l'ADN |
Motif structural |
| Histone-fole, Putative DNA-binding domain, Replication modulator SeqA, C-terminal DNA-binding domain, Skn-1, Phage replication organizer domain | mainly α | --------- |
| Leucine zipper domain, HLH, helix-loop-helix DNA-binding domain | Helix-loop-helix | |
| Homeodomain-like, lambda repressor-like DNA-binding domains, HMG-box, C-terminal effector domain of the bipartite response regulators, TrpR-lk, Sigma3 and sigma4 domains of RNA polymerase sigma factors, T4 endonuclease V, KorB DNA-binding domain-like, ARID-like | Helix-turn-helix | |
| Winged helix DNA-binding domain | mainly α with a small β-ribbon (wing) | Winged Helix-turn-helix |
| WD40 repeat-like | mainly β | --------- |
| p53-like transcription factors | Immunoglobulin-like β-sandwich | |
| TATA-box binding protein-like | TBP β-sheet | |
| E set domains | Immunoglobulin-like β-sandwich | |
| Chromo domain-like, Transcription factor IIA (TFIIA), AbrB/MazE/MraZ-like | β-barrel | |
| Uracil-DNA glycosylase-like, His-Me finger endonucleases, IHF-like DNA-binding proteins, RNase A-like, DNase I-like, SRF-like, Viral DNA-binding domain, UDP-Glycosyltransferase/glycogen phosphorylase, FMT C-terminal domain-like, Methylated DNA-protein cysteine methyltransferase domain, 5' to 3' exonuclease catalytic domain, Transposase IS200-like, Bet v1-like, DNA-binding domain of intron-encoded endonucleases, Cryptochrome/photolyase FAD-binding domain, SMAD MH1 domain, Xylose isomerase-like, Holliday junction resolvase RusA | mixed α/β | --------- |
| Glucocorticoid receptor-like, C2H2 and C2HC zinc fingers, Zn2/Cys4 DNA-binding domain, Zn2/Cys6 DNA-binding domain, Zinc finger design, Retrovirus zinc finger-like domains | Zinc finger | |
| Ribbon-helix-helix, PIN domain-like | Ribbon-helix-helix | |
| GCM domain | β-sheet | |
| DNA/RNA polymerases, nucleotidyltransferase, Ribonuclease H-like, Lesion bypass DNA Polymerase, DNA repair protein MutS, DNA breaking-rejoining enzymes, P-loop containing nucleoside triphosphate hydrolases, DNA/RNA polymerases, replication terminator protein (Tus), DNA topoisomerase IV, α subunit, Metallo-dependent phosphatases, RNA polymerase, ATP-dependent DNA ligase DNA-binding domain, Thioredoxin-like | multidomain, mixed α/β | --------- |
| DNA-binding domains of HMG-I(Y) | peptide | AT-hook |
| Le motif "AT-hook" est constituée d'une séquence palindromique conservée dont le coeur est Pro-Arg-Gly-Arg-Pro avec un nombre variable de Lys et Arg chargées positivement de chaque côté de la séquence de base. Ce motif se fixe dans le petit sillon d'ADN riche en adénine et thymine (AT) d'où son nom. | ||
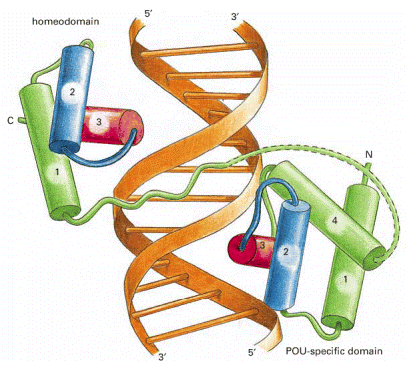
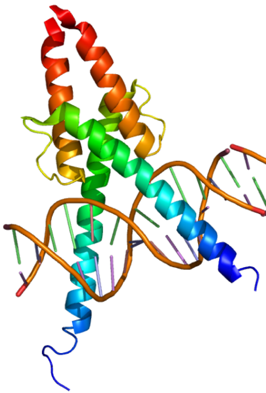
c. Homéodomaine, boîte homeobox et domaine POU Un homéodomaine est un repliement qu'adoptent de nombreux FT qui se fixent sur l'ADN ou l'ARN. Il est présent exclusivement chez les Eucaryotes (transformations corporelles homéotiques, morphogénèse, développement). C'est un domaine protéique (PFAM PF00046) hautement conservé qui adopte une structure hélice-tour-hélice ("helix-turn-helix" - HTH) de 60 acides aminés dans laquelle 3 hélices alpha sont reliées par des boucles courtes.
Source : Alberts et al. Les 2 hélices N-terminales sont antiparallèles et l'axe de l'hélice C-terminale est à peu près perpendiculaire à celui des deux premières. L'hélice C-terminale est plus longue et elle est riche en Arg et Lys qui établissent des liaisons hydrogènes avec l'ADN. Par exemple, la chaîne latérale de Arg peut établir 2 liaisons hydrogène avec la base azotée guanine au sein du grand sillon de l'ADN, mais pas avec d'autres bases azotées. Les acides aminés hydrophobes conservés au centre de l'hélice C-terminale accroissent sa compaction. L'homéodomaine se fixe donc à l'ADN de type B (avec une préférence pour la séquence 5'-ATTA-3') via l'hélice C-terminale qui s'aligne dans le grand sillon de l'ADN et via l'extrémité N-terminale non structurée qui s'aligne dans le petit sillon. Une boîte homeobox (gènes HOX) est une séquence d'ADN d'environ 180 paires de base des gènes qui codent les protéines contenant un homéodomaine. Le domaine POU est trouvé dans une famille de protéines qui contiennent des homéodomaines très conservés. L'acronyme POU est dérivé des noms de 3 FT :
|
d. Motif hélice-boucle-hélice ("basic helix-loop-helix" - bHLH) Ce motif (PFAM PF00010) est composé de 60 acides aminés :
Source : Wikipedia En général, les FT qui possèdent ce domaine forment des dimères : l'une des hélices est souvent plus petite et la flexibilité de la boucle permet la dimérisation par compaction contre l'autre hélice. La plus grande hélice contient généralement les sites de fixation à l'ADN sur une séquence consensus appelée "E-box" (5'-CANNTG-3') dont la séquence canonique est un palindrome appelée "G-box" (5'-CACGTG-3'). Exemples de FT qui possèdent ce domaine : C-Myc, N-Myc, MyoD, Myf5, scleraxis, neurogenines, OLIG1, OLIG2 |
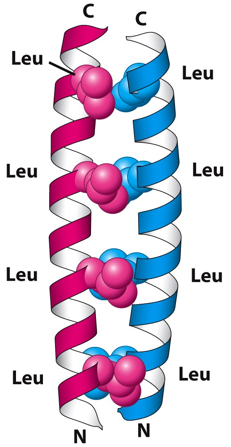
e. Les structures "coiled coil" et le motif "leucine zipper" Une structure dite "coiled coil" (bobine enroulée) est une structure des protéines, où les hélices α sont enroulées l'une dans l'autre comme les brins d'une corde tressée. Ces hélices contiennent 3,5 résidus d'acides aminés par tour. Les dimères et les trimères d'hélices sont les types les plus courants. Cette structure a été proposée indépendamment par Linus Pauling et Corey, et par Crick en 1953.
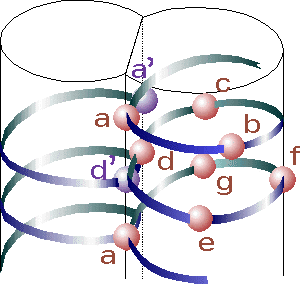
Source : "Oregon state University" Un domaine "leucine zipper" est une structure de type "coiled coil" : c'est une structure super-secondaire constituée de deux hélices alpha parallèles enroulées l'une dans l'autre sur la gauche ("left-handed parallel dimeric coiled-coil") et stabilisée par des résidus leucine. Le domaine "leucine zipper" est le domaine de dimérisation des facteurs de transcription de la super-classe bZIP ("Basic helix-loop-helix/leucine zipper") des Eukaryotes. Cette super classe contient les classes ou familles suivantes : "Leucine zipper factors", "Helix loop helix factors", "Helix loop helix/leucine zipper factors", "NF family", "RF-X family" et "bHSH family". Les facteurs de transcription CREB ("cAMP response element-binding protein") et GCN4 ("General control protein GCN4") appartiennent également à la super-classe bZIP. Une structure "coiled coil" contient un motif répété de sept acides aminés ("heptad repeat") dont la nomenclature est (abcdefg)n, où a et d sont des acides aminés hydrophobes.
Source : "The heptad repeat of the coiled-coil structure" Au sein du domaine "leucine zipper", à chaque deuxième tour d'hélice une leucine est en contact direct avec une leucine de l'autre hélice. Les hélices alpha des structures "coiled coil" sont dites amphipathiques :
|
f. Le motif "Zinc finger" ("doigt de zinc") Le motif en doigt de zinc est un motif de fixation à l'ADN constitué de Cys et His espacées de manière spécifique et qui se lient à des atomes de zinc (exemples : TFIIIA et les FT de la famille des hormones stéroïdes). Les protéines qui ont un motif Zinc finger sont trés diverses et ne se limitent pas aux facteurs de transcription. En effet, certaines sont impliquées dans la fixation d'autres protéines qui interviennent dans de très nombreux processus biologiques (réplication et réparation, transcription et traduction, métabolisme et signalisation, prolifération cellulaire et apoptose, ...). Il existe donc plusieurs types de repliement des domaines avec un motif Zinc finger : |
| Motif Zinc-finger | caractéristiques | Exemples de protéines et code PDB |
| Cys2His2 | Motif le plus courant des FT des Mammifères dont la séquence consensus est Cys-X2,4-Cys-X3-Phe-X5-Leu-X2-His-X3-His. Chaque motif Zinc finger (environ 30 acides aminés) est composé d'une courte épingle à cheveux β N-terminale puis d'une petite boucle et d'une hélice α. Sa structure est stabilisée par 2 Cys et 2 His liées à un atome de zinc. |
1NCS, 1ZFD, 1TF6, 1UBD, 2GLI, 1BHI |
| "Gag knuckle" | Il ressemble au motif Cys2His2 mais il est plus court (environ 20 acides aminés). | Protéines rétrovirales gag (nucléocapside) |
| "Treble clef" | Motif composé d'une épingle à cheveux β N-terminale et d'une hélice α C-terminale. | |
| "Zinc ribbon" | Motif composé de deux épingles à cheveux β et un feuillet β antiparallèle à 3 brins (liaisons hydrogène avec l'une des deux épingles). C'est le groupe qui contient le plus de types de repliements différents. | Facteur d'initiation de la transcription TFIIB (1PFT), facteur d'élongation de la transcription TfIIS (1TFI) |
| Zn2/Cys6 | Protéines de régulation de la transcription Gal4 (1D66A), Ethanol regulon transcriptional activator (2ALCA) | |
| "TAZ2 domain like" | Le repliement des domaines TAZ ("Transcription Adaptor putative Zinc finger") est tout α. |
CBP ("CREB-binding protein") et p300 : histones acétyltransférases (EC 2.3.1.48) qui catalysent l'acétylation réversible des histones dans les nucléosomes pour réguler la transcription via le remodelage de la chromatine (1L8C) |
|
Visualisation de la structure Zinc finger de Zif268 de Mus musculus à une résolution de 2,1 Å Code PDB : 1ZAA |
5. Les récepteurs nucléaires a. Rôle et mode d'action des récepteurs nucléaires Il en existe plus de 150 repertoriés, dont 48 connus chez l'homme. Voir la base de données des récepteurs nucléaires : "NURSA" - The Nuclear Receptor Signaling Atlas Un grand nombre de récepteurs nucléaires ont un rôle de facteur de transcription : ce sont des protéines qui agissent dans le noyau (en relayant des signaux hormonaux) et qui modulent l'expression des gènes. Ces récepteurs agissent en trans : ils induisent l'expression de gènes codant des protéines qui à leur tour activent de nombreux autres gènes. Certains récepteurs nucléaires ont un autre rôle en agissant sur d'autres voies de signalisation intracellulaire. Les récepteurs nucléaires peuvent être classés en deux principales catégories selon leur mécanisme d'action et leur distribution sub-cellulaire en absence de leur ligand. - les récepteurs nucléaires de type I situés dans le cytosol puis délocalisés dans le noyau :
- les récepteurs nucléaires de type II :
Il existe 2 autres catégories "mineures" de récepteurs nucléaires :
|
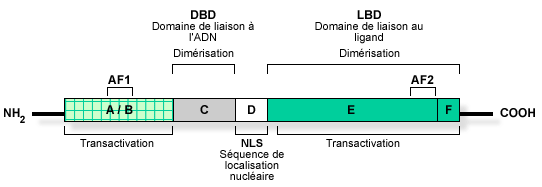
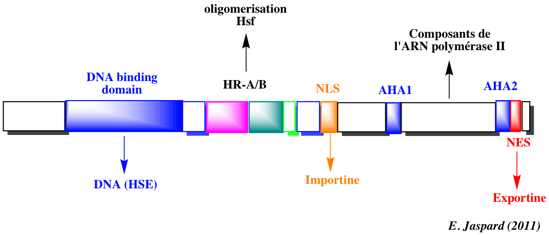
b. Structure des récepteurs nucléaires Ils ont une structure globale conservée. Ils sont constitués de 2 domaines :
Source : "Activation des récepteurs nucléaires"
Les récepteurs nucléaires peuvent être classés en 4 catégories (voir ci-dessus) en fonction du type de dimérisation et des séquences d'ADN reconnues. Les acides aminés impliqués dans la dimérisation des récepteurs pour leur activité transcriptionnelle, se trouvent dans les domaines C et [E / F]. La séquence en acides aminés appelée signal de localisation nucléaire ("Nuclear Localisation Signal" - NLS) permet au récepteur d'être adressé au noyau et d'y rester. |
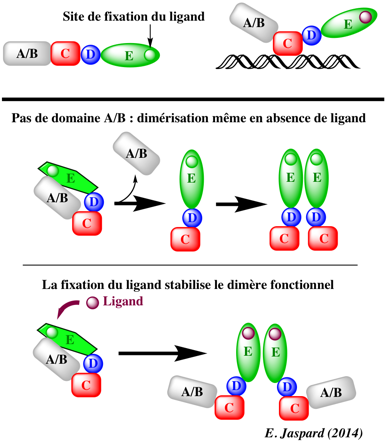
Une fois activés, ces récepteurs se fixent sur l'ADN sous forme d'homo- ou d'hétérodimères. Figure ci-dessous : relation entre dimérisation des récepteurs nucléaires et la fixation de leurs ligands.
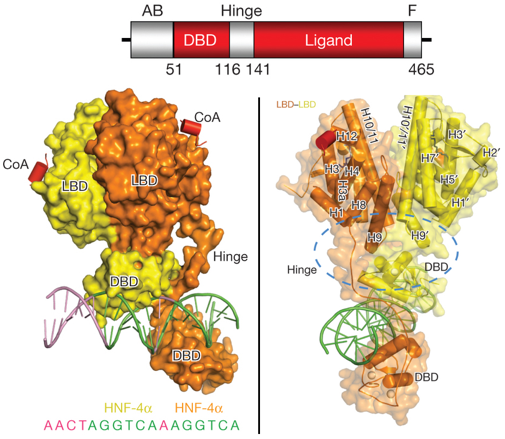
L'absence de domaine A/B permet la dimérisation même en absence du ligand. La fixation du ligand s'oppose à l'inhibition qu'exerce le domaine A/B sur la dimérisation des domaines E en stabilisant la conformation du dimère. Voir ci-dessous le mode d'activation des récepteurs nucléaires. Figure ci-dessous : structure cristalline (résolution 2.9 Å) des multiples domaines de HNF-4α humain (sous forme d'homodimère) fixé à son élément de réponse et à des peptides co-activateurs.
Source : Chandra et al. (2013) Une arginine cible de la méthylation par PRMT1 et une serine cible de la protéine kinase C contribuent au maintien des interactions entre domaines. Ces modification post-traductionnelles induisent un changement de la fixation de l'ADN. Le récepteur "Hepatocyte Nuclear Factor 4α" (HNF-4α ou NR2A1) est un récepteur nucléaire - facteur de transcription. HNF-4α est la protéine se fixant à l'ADN la plus abondante dans le foie où environ 40% des gènes transcrits possèdent un élément de réponse à HNF-4α. Ces gènes sont impliqués en grande partie dans la néoglucogénèse et le métabolisme des lipides. Les mutations de HNF-4α sont donc liées à l'hypoglycèmie hyperinsulinèmique et au diabète de type 1. |
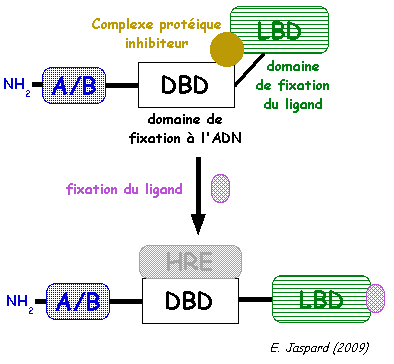
c. Mode d'activation des récepteurs nucléaires Tant que le récepteur n'a pas fixé le ligand, il est dans une conformation inactive car le domaine DBD est bloquée par un complexe protéique inhibiteur. Quand le domaine LBD a fixé le ligand, il change de conformation et l'inhibiteur est relargué. Le domaine DBD est libre et il se fixe sur la séquence d'ADN spécifique HRE, ce qui induit l'activation de la trancription des gènes.
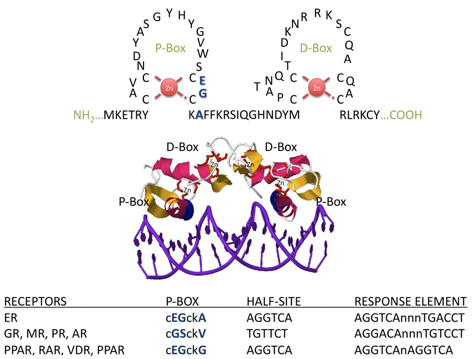
Les domaines DBD sont des séquences d'environ 66 à 68 acides aminés, dont 9 cystéines conservées, qui adoptent une structure en doigt de zinc de type C4 (4 cystéines).
Source : Nuclear hormone receptors La structure hélicoïdale de la "P-box" permet des contacts avec le grand sillon de l'hélice d'ADN. Les acides aminés de la "D-box" sont importants pour les interactions avec les groupements phosphates de l'ADN et pour la dimérisation du récepteur. |
d. Quelques ligands importants des récepteurs nucléaires Des petites molécules lipophiles peuvent traverser la membrane plasmique ou entrer dans le noyau (via les pores nucléaires) et donc entrer dans les cellules. Les médiateurs de ces petites molécules lipophiles sont les récepteurs nucléaires. Ces petites molécules lipophiles contrôlent donc indirectement de nombreux processus biologiques (reproduction, développement, métabolisme, inflammation, fonctions immunitaires, ...) chez les Eucaryotes. Ces petites molécules lipophiles sont essentiellement :
Voir une liste très complètes des récepteurs nucléaires connus chez l'homme. Certains récepteurs nucléaires n'ont pas de ligand identifié : ils sont dit "orphelins". |
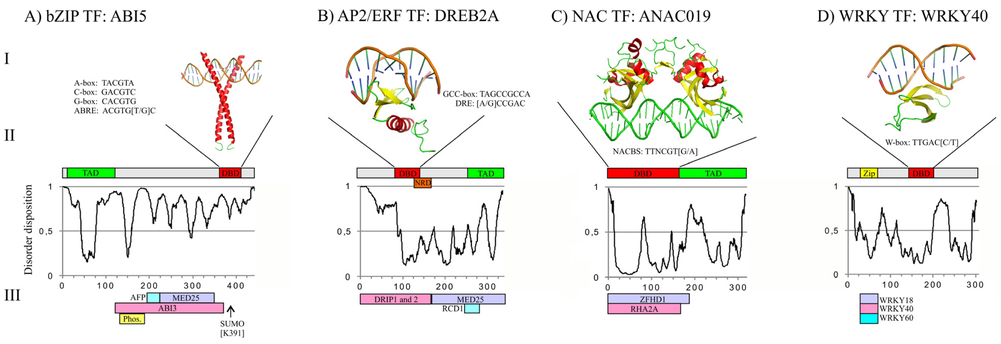
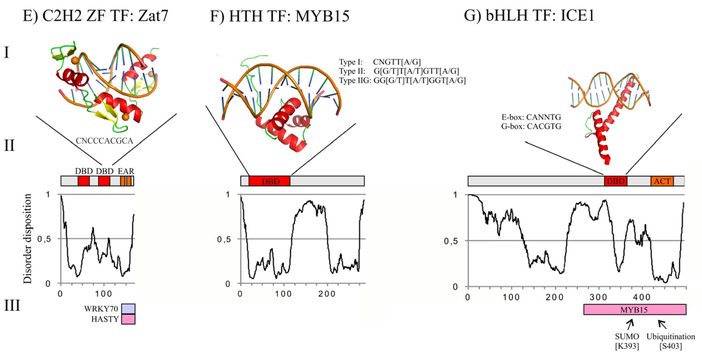
Structure de membres des familles bZIP, AP2/ERF, NAC, WRKY, ZF C2H2, HTH et bHLH Figure ci-dessous :
Source : Chandra et al. (2013)
Figure ci-dessous :
Source : Chandra et al. (2013)
Très souvent, les TF contiennent un domaine de régulation de la transcription ("Transcription Regulatory Domain" - TRD) et un domaine d'activation de la transcription ("Transcriptional Activation Domain" - TAD). Les TRD ont souvent un taux élevé de séquences de faible complexité et sont donc caractérisés par des régions intrinséquement non structurées avec un désordre intrinsèque ("Intrinsic Disorder" - ID). |
| 7. Liens Internet et références bibliographiques |
| "Communications et signalisations cellulaires" Y. Combarnous (2004) Ed. Lavoisier - ISBN : 2-7430-0654-4 | |
|
The Nuclear Receptor Signaling Atlas Plant Transcription Factor Database Stress responsive TranscrIption Factor Database Database of Arabidopsis Transcription Factors Transcription factor binding sites profiles database |
|
|
Krishna et al. (2003) "Structural classification of zinc fingers" Nucl. Acids Res. 31, 532 - 550 Foat et al. (2006) "Statistical mechanical modeling of genome-wide transcription factor occupancy data by MatrixREDUCE" Bioinformatics 22, e141 - e149 Pan et al. (2010) "Mechanisms of transcription factor selectivity" Trends Genet. 26, 75-83 Rohs et al. (2010) "Origins of Specificity in Protein-DNA Recognition" Ann. Rev. Biochem. 79, 233 - 269 |
|
|
Rastinejad et al. (2013) "Understanding nuclear receptor form and function using structural biology" J. Mol. Endocrinol. 51, T1-T21 Yamasak et al. (2013) "DNA-binding domains of plant-specific transcription factors: structure, function, and evolution" Trends Plant Sci. 18, 267–276 Lindemose et al. (2013) "Structure, Function and Networks of Transcription Factors Involved in Abiotic Stress Responses" Int. J. Mol. Sci. 14, 5842 - 5878 Villar et al. (2014) "Evolution of transcription factor binding in metazoans - mechanisms and functional implications" Nat. Rev. Genet. 15, 221 - 233 |
|
|
Grygiel-Gorniak B. (2014) "Peroxisome proliferator-activated receptors and their ligands: nutritional and clinical implications" Nutrition J. 13, 17 Yang et al. (2014) "TFBSshape: a motif database for DNA shape features of transcription factor binding sites" Nucl. Acids Res. 42, D148-D155 Shazman et al. (2014) "OnTheFly: a database of Drosophila melanogaster transcription factors and their binding sites" Nuc. Acids Res. 42, D167 - 71 |
|
|
Lambert et al. (2018) "The Human Transcription Factors" Cell 172, 650 - 665 Panigrahi & O'Malley (2021) "Mechanisms of enhancer action: the known and the unknown" Genome Biol. 22, 108 Henley & Koehler (2021) "Advances in targeting 'undruggable' transcription factors with small molecules" Nat. Rev. Drug Discov. 20, 669 - 688 |
|
![]()
{kind=link}
{kind=link}
{kind=link}